Teil 2: Training des neuronalen Netzes
Von der Biologie zum Computer
In diesem zweiten Teil übertragen wir die biologischen Abläufe auf den Computer.
Die Netzhaut wird ersetzt durch eine Kamera mit z.B. 20 Megapixeln. Die Schichten der neuronalen Netze werden im Computer programmiert ebenso wie die Übergangswahrscheinlichkeiten der Synapsen.
Das überwachte Lernen geschieht durch bekannte Bildeingaben mit Anlernen der einzelnen Begriffe:
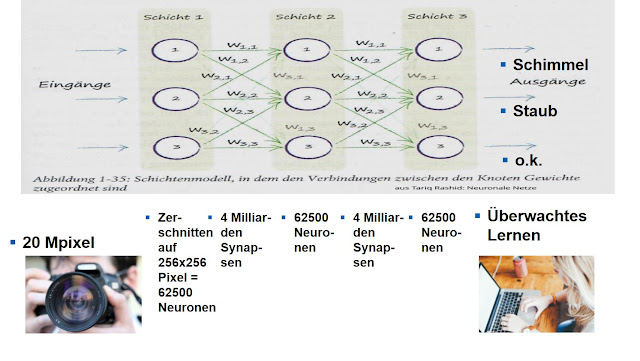 |
Übertragung des Blockschaltbildes für Neuronale Netze auf den Computer
|
Die genannten Zahlen sind nur Anfangsbeispiele, die wirklichen Zahlen kommen später nach einer intensiven Trainingsphase. Aktuell sind dies 38.650.337 Parameter.
Für die Bildverarbeitung werden neuronale Netze um eine weitere Eigenschaft, nämlich der Faltung ergänzt. Dabei wird das Eingangsbild stufenweise gefiltert und in seine Merkmale von einfach bis komplex zerlegt. Das nachgeschaltete neuronale Netz identifiziert dann aus den komplexen Merkmalen das Eingangsbild. Im nachfolgenden Bild ist als Beispiel eine Katze gezeigt:
Aus dem Bild der Katze werden zunächst die ganz einfachen Merkmale extrahiert. Die nächst höhere Stufe setzt dann ein neues komplexeres Merkmal aus den ganz einfachen Merkmal zusammen. Diese werden dem neuronalen Netz zur Erkennung übergeben.
Ganz korrekt wird dies in folgendem Bild dargestellt:
 |
Darstellung des Ablaufes beim Anlernen von faltenden neuronalen Netzen
|
Anwendungen für das Training der faltenden neuronalen Netze
In zahlreichen Kirchen wurden viele Fotos von Fehlerbildern im Umfeld von Kulturgütern gemacht. Hierzu gehören z.B. Schimmel, Staub, Wasser, Insekten, Dreck und Fotos ohne Fehlerbild. Die Träger sind normalerweise Holz, Textilien und Glas auf verschiedenen Objekten wie Altäre, Orgeln, Gestühle, Skulpturen und Gemälde. Zusammen mit eingesandten Fotos von Unterstützern des Projektes kommen über 2000 Fotos zusammen. Eine Auswahl an Originalfotos ist in folgendem Bild zu sehen:
 |
Beispiel-Fotos für das Training der neuronalen Netze
|
Die Beispiele zeigen Fotos mit Schwerpunktthemen in Schimmel und Staub. Schaut man genau hin, so erkennt man, daß auch mehrere Fehlerbilder auf jedem Foto erkennbar sind. Aus diesem Grund werden die Bilder geschnitten, damit möglichst nur ein Fehlerbild im geschnittenen Foto erkennbar ist. Ein weiterer Grund ist die stark steigende Rechenzeit beim Training der neuronalen Netze, wenn die Zahl der Pixel zu groß wird. Das folgende Bild zeigt Beispiele für geschnittene Bilder:
 |
Beispiele für geschnittene Fotos mit möglichst nur einem Fehlerbild
|
Diese Bilder müssen nun sortiert werden in die einzelnen Fehlerkategorien. Bis heute sind dies knapp 300.000 geschnittene Fotos, die manuell (!!!) geladen, angesehen und in die entsprechenden Ordner einsortiert werden müssen.
Bilder der Fehlerkatagorie Schimmel
 |
Bilder der Fehlerkategorie Schimmel
|
Bilder der Fehlerkategorie Staub
 |
Bilder der Fehlerkategorie Staub
|
2000 dieser Bilder von Schimmel, Staub, o.k. werden in die Algorithmen eingelesen und es wird ein erster Durchlauf (Epoche) gestartet. Die Ergebnisse des Durchlaufs werden dann als korrekt oder nicht korrekt bewertet. Wenn das neuronale Netz ein falsches Ergebnis geliefert hat, kann es mit dieser Bewertung seine Übergangswahrscheinlichkeiten neu justieren. Die Korrektheitsrate gibt an, wie gut die Erkennungsrate ist. Je höher der Wert, desto besser die Erkennungsrate. 0 % bedeutet, daß kein Bild richtig erkannt wird und bei 100 % werden alle Bilder richtig erkannt.
 |
Korrektheitsrate beim Training der neuronalen Netze
|
Beim ersten Durchlauf liegt der Wert bei etwa 90% (das ist die gepunktete Kurve). Diese Zahl bezieht sich auf die Erkennungsrate aller beliebig gezeigten Bilder mit Schimmel und Staub.
Nun werden je 100 andere Bilder, die nicht im Training verwendet wurden, zur Validierung eingegeben. Beim ersten Durchlauf liegt die Erkennungsrate bei 87% (durchgezogene Kurve).
Nun finden weitere Durchgänge (Epochen) statt. Wieder werden die gleichen Trainingsbilder (anders gemischt und mit Datenaugmentation leicht verändert) gezeigt und die Korrektheitsrate steigt über 95% bis ca. 100% an.
Die Validierungsrate (diese Bilder sind immer gleich) schwanken etwas.
Insgesamt werden 32 Epochen durchgeführt bis keine weitere Ergebnisverbesserung mehr stattfindet.
Für die weitere Untersuchung wird dann der Datensatz mit den dort berechneten Übergangswahrscheinlichkeiten genommen, der das beste Ergebnis für die Validierung brachte, hier z.B. Datensatz 10.
Mit der Gewichtsfunktion von Datensatz 10 werden nun ganz neue Bilder bewertet. Je 100 dem System unbekannte Testbilder mit Schimmel und Staub werden eingelesen und die Abweichung im unten stehenden Bild dargestellt. Staub liegt bei Label 0 und Schimmel liegt bei Label 1. Es zeigen sich eine Abweichungen, beide Klassen werden gut erkannt.
 |
Finales Testergebnis des Trainings der neuronalen Netze
|
Ergebnis: Bereits bei der ersten Version der Algorithmen wird eine überraschend hohe Erkennungsrate erreicht. Aber Probleme werden ganz sicher in den weiteren Analysen kommen. Noch wurden 298000 geschnittene Fotos nicht ausgewertet.
Danksagung:
Diese Arbeiten werden von der DBU gefördert unter Aktenzeichen 35604/01 "Entwicklung und modellhafte Anwendung einer Systemplattform zur automatischen Detektion von durch anthropogene Umwelteinflüsse verursachter Schimmelbildung an Kulturgütern mittels künstlicher Intelligenz". Wir bedanken uns an dieser Stelle nochmals herzlich für die Förderung des Projektes.
Ansprechpartner:
Michael Robrecht und Markus Böger, iXtronics GmbH, Paderborn
Hans Daams, Hajuveda Heritage, Monschau
Direktkontakt:
hans.daams@hajuvda.solutions
michael.robrecht@ixtronics.com
markus.boeger@ixtronics.com
Webadressen:
https://www.hajuveda.solutions
https://ix.ixtronics.com/de/
Blog:
https://custosaeris-d.blogspot.com










Kommentare
Kommentar veröffentlichen